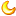AlphaGo与人类的恩怨情仇(3)-初试啼声:(上)
2017年6月8日 棋艺探索
本文首发于知乎专栏——不一样的围棋,作者,不会功夫的潘达
关于AlphaGo,我们从头讲起。2010年,德米斯·哈萨比斯(Demis Hassabis)离开伦敦大学学院(UCL),与Shane Legg、Mustafa Suleyman共同创立了DeepMind公司。随后的几年里,DeepMind完成了数项重要成果。2014年初,声名鹊起的DeepMind被谷歌以4亿欧元(6.5亿美元)的价格收购。同年,AlphaGo项目启动。
在当时,DeepMind并没有为AlphaGo制定具体的目标。曾经的优秀国际象棋手哈萨比斯对于开发围棋AI的难度有深刻认识: 国际象棋的游戏树复杂度(即“香农数,Shannon Number”)约为10^120. 所谓游戏树复杂度,就是不同棋局的总数,可以用国际象棋的平均游戏长度(约40回合)乘以每个回合的平均变化数(约10^3种)估算得到。注意,游戏树复杂度和局面总数并不相同。国际象棋大约有10^40种局面,而将不同的几十个局面串联在一起,才是一局棋。换句话说,一个局面就是游戏树上的一片叶子;把所有的叶子用枝杈连在一起,方成一棵游戏树。
(图为井字棋游戏树的一部分,来源:https://www.cs.cmu.edu)
因此,游戏树复杂度比局面总数大很多。围棋的合法局面总数为2.0*10^170,而对应的游戏树复杂度达到3*10^511. 这还是一个非常保守的估计。须知,可观测宇宙的原子总数不过10^80个。这意味着任何形式的穷举,或者暴力搜索,对于围棋都是不现实的。在本系列的上一篇中也提到,围棋手的决策一定程度上依靠直觉,这是很难被人工智能模仿的。
围棋问题的高难度并没有吓走DeepMind,因为他们手上有先进的工具:深度学习。2015年2月,DeepMind在《自然》杂志发表论文,宣布DQN(Deep Q-Network)项目的成功。在DQN项目中,DeepMind团队采用深度强化学习,让AI从零开始学会了玩各种街机游戏,和最优秀的人类玩家操作得一样好。哈萨比斯常以“打砖块”游戏展示深度学习的力量。
(打砖块游戏截屏)
在初始条件下,AI对打砖块一窍不通,甚至都接不到球。但在失败中,AI似乎慢慢学到了些什么,开始接球、控制球的方向,直到最后,掌握了秘笈:打通边缘一列的砖墙,然后就可以让球反复在砖墙上边反弹而不下落,无风险坐收分数。整个学习过程没有任何人工干涉。此前类似的成果,都有人工干涉的成分。相形之下,深度强化学习,让打街机的AI向真正的智能前进了一小步。
如果说深度学习是一把力重千钧的大锤,能够像锤钉子那样征服一个又一个的难题,那么围棋无疑是最顽固的一枚钉子。DeepMind团队起初并无征服围棋的雄心,只想看看他们能走到哪一步。然而,新技术的力量让这些世界上最优秀的工程师们都感到吃惊。半年多过去,团队里棋力最强的高级研究员、台湾业余6段棋手黄士杰也下不过AlphaGo了。不仅如此,AlphaGo在与其它商业围棋软件(Zen, Crazystone)的对战中,让四子仍能取得99%的胜率。要知道,武宫正树让Zen四子还曾输掉一局。种种迹象表明,AlphaGo很可能已经达到了职业水平。
当然,AlphaGo是否真的达到职业水平,还要通过一名真正职业棋手的检验。三届欧洲冠军、职业二段棋手樊麾被选为AlphaGo的第一块试金石。
樊麾,1981年出生于中国,1996年通过定段赛成为职业棋手,1998年升为职业二段。目睹自己与古力等天才棋手在天赋上的差距,樊麾觉得继续做职业棋手的前途并不理想。心怀见识更大世界的念头,不满19岁的樊麾只身前往法国,学习酒店管理。刚到法国的前几年,樊麾有意让自己忘记围棋,一门心思扑在专业课和语言的学习上。等到学业变得顺畅之时,樊麾却想重新拾起围棋。“我一直和会下棋的人说,这东西,沾上了就戒不掉”,樊麾如是说。好在当时的欧洲已不是围棋的荒漠,法国的围棋俱乐部遍地开花,其中的高手也有相当于中国业余5段的水平。樊麾一面担任法国国家围棋队的教练,一面在赛场上力挫群雄。2013年,樊麾加入法国籍,其后在2013-2015年三夺“欧洲冠军”头衔。
在纪录片《AlphaGo》中,樊麾骑自行车穿过法国小巷,赶到一处街头棋摊,与当地爱好者下一对三的指导棋。棋局进行中,樊麾接到了来自哈萨比斯的电话,邀请他参与围棋软件的开发测试。樊麾虽很疑惑,但就如同十五年前赴法留学一样,喜欢探索未知的樊麾说走就走,登上了前往英国的飞机。樊麾半开玩笑半认真地说,当他接到邀请时,他以为工程师们会在他的脑袋上贴满电极片,以研究棋手的大脑内部构造。结果完全不是这么一回事。DeepMind竟然要让一个围棋软件挑战他,还是正式的对抗!“只不过是一个软件而已,”樊麾想。没有太多犹豫,樊麾接受了挑战。
樊麾与AlphaGo的对抗赛共计十局。其中五局为正式局,使用较长的限时,并计入总比分;另五局为非正式局,使用较短的限时,不计入总比分。正式局和非正式局的AlphaGo配置完全相同(除用时外)。比赛在2015年10月5日-10月9日间进行。
从事后看,在五盘正式对局中,首局大概是樊麾发挥最好的 。
樊麾(黑) – AlphaGo (白)对抗赛第一局, 1-30手。
这盘棋的开局,双方在三个角上摆了三个不同的简单定式。左下角的定式,曾在上个世纪流行,但在21世纪基本已被淘汰。现代棋手的看法是,黑棋5、7、9三子的组合过于坚实,效率偏低。右上角的“双枪定式”,通常是初学者学到的第一个定式。现代棋手同样认为黑棋速度稍慢,略有不满。职业棋手对定式看法的变化,一方面是在大量实战中加深了认识,另一方面与规则的变化有关。从上世纪80年代到今天,黑棋的贴目负担加重。中国规则由黑贴2.75子变为黑贴3.75子(大致相当于7.5目),日本、韩国规则由黑贴5.5目变为黑贴6.5目。大贴目的负担,逼迫黑棋加快布局的速度;须快速展开阵型,而不是像图中5、7、9一样龟爬。
而本局中国规则黑贴3.75子的背景下,持黑棋的樊麾执意“复古”,大概是有一种对AlphaGo的“上手”心态。心态放松,所以开局稍亏一点点也不太在意。
11-60手。
随着棋局进行,樊麾很快意识到他的对手并不简单。白方36-42手法坚实,在黑方的势力范围内硬生生开辟出一片根据地。虽然黑方43-51还以颜色,也掏掉白棋下边的空,但白方右上52-56再占便宜。随后,AlphaGo用白58小秀一把“棋型的感觉”。这招棋的目的是补住K4位的断。与笨拙的M3位粘相比,白58极具视觉效果,不落俗套。从效果来看,这未必是最佳的一手,却能让棋盘对面的樊麾疑惑:莫非AI也理解什么棋型丑陋,什么棋型优雅?
之后的棋局并无激烈战斗,双方各自鸣金收兵之后便进入官子争夺。这里最值得注意的是下图的这一招。
白130,精妙的手筋。借此,白棋先手将Q18一子连回。此手一出,大概樊麾就知道自己要输了吧。
终局画面如图。AlphaGo以1.25子的优势取胜,差距并不大。樊麾布局时稍稍松懈,使得整盘棋只能追赶。然而AlphaGo基本功扎实,在一盘比拼内力的功夫棋中未给樊麾反超的机会,笑到最后。该终局画面也在三个月之后登上了《自然》杂志的封面。
|
附件:
您需要登录才可以下载或查看附件。没有帐号?注册